Method: Parallel Monoid Scan
ELSA transforms the sequential online softmax recurrence into a fully parallelizable computation by proving that attention states $(m, S, W)$ form an associative monoid under a merge operator $\oplus$.
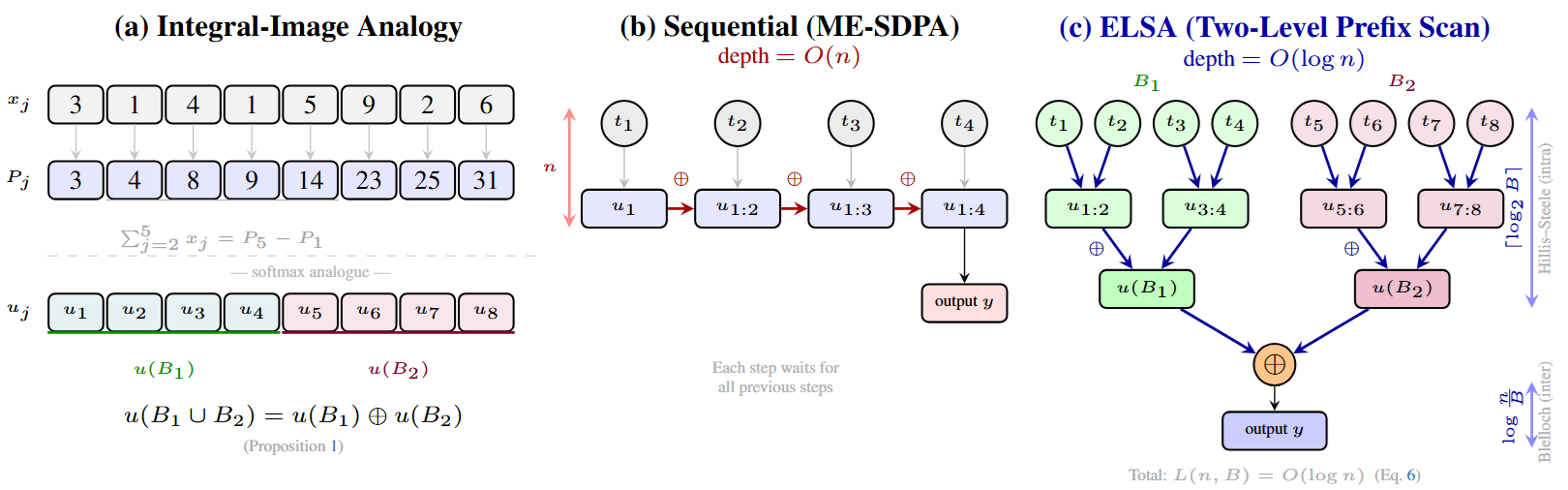
From Sequential Recurrence to Parallel Scan
Classical ME-SDPA chains tokens one by one: each step depends on the previous running maximum $m_j$, forcing $O(n)$ sequential depth. ELSA breaks this chain by observing that any two contiguous blocks can be merged exactly via:
$u_A \oplus u_B = \mathrm{renorm}\!\left(\max(m_A, m_B),\; \tilde{S}_A + \tilde{S}_B,\; \tilde{W}_A + \tilde{W}_B\right)$
Two-Level GPU Scan
- Intra-block (Hillis–Steele): Each thread block independently reduces 128 tokens in shared memory using a tree scan.
- Inter-block (Blelloch): A work-optimal two-pass scan aggregates block-level states in global memory, adding only $2\lceil\log_2(n/B)\rceil$ merge levels.
Total scan depth: $L(n, B) = \lceil\log_2 B\rceil + 2\lceil\log_2(n/B)\rceil + 3 \leq 2\lceil\log_2 n\rceil + 3$, with a provable FP32 relative error of $O(u \log n)$.
GPU Memory Hierarchy — Token Movement
The animation below visualises how ELSA moves tokens through the GPU memory hierarchy compared to ME-SDPA (xFormers FP32). Left: ME-SDPA loads one tile at a time sequentially (O(n) depth). Right: ELSA loads 64 tiles in parallel across 8 SRAM blocks, runs Hillis–Steele intra-block scans (log₂8 = 3 levels), then a Blelloch inter-block sweep—achieving O(log n) = 6 steps with no Tensor Core dependency.